Pandas - 복사, 추가, 통계값, 피벗테이블, 인덱스
[참조] 패스트캠퍼스 - 직장인을 위한 파이썬 데이터분석 올인원 패키지 Online.
pandas 복사
흔히 코드 상에서 복사를 할 때는 새로운 변수에 원래 값을 넣어주어 복사를 한다.
new_df = df
값이 들어있는 DataFrame을 복사하기 위해서는 위 방식으로 하면 될 것 같지만 그렇지 않다.
new_df와 df 모두 같은 메모리를 참조하기 때문에 new_df를 수정하면 df도 수정이 된다.
copy_df = df.copy()
위 메서드를 이용해 복사를 할 수가 있다.
pandas row, column 추가 및 삭제
row 추가
df = df.append({'이름': '테디', '그룹': '테디그룹', '소속사': '끝내주는소속사', '성별': '남자', '생년월일': '1970-01-01', '키': 195.0, '혈액형': 'O', '브랜드평판지수': 12345678}, ignore_index=True)
append()함수 사용- Dictionary 형태의 데이터 Input
- Ignore_index=True 옵션 추가
column 추가
df['국적'] = '대한민국'
- 국적이라는 열을 생성하고 해당 열에 모두 대한민국이라는 값을 추가
값을 변경하고 싶다면 아래와 같이 loc 함수를 이용해 변경 가능하다
df.loc[df['이름'] == '지드래곤', '국적'] = 'Korea'
pandas 통계값
min(최소값)
df['키'].min()
max(최대값)
df['키'].max()
sum(합계)
df['키'].sum()
mean(평균)
df['키'].mean()
var, variance(분산) / std, standard deviation(표준편차)
분산과 표준편차는 데이터가 평균으로부터 얼마나 떨어져 있는지 정도를 나타낸다.
분산: (데이터 - 평균)^2을 모두 합한 값
data = np.array([1, 3, 5, 7, 9]) data.var()df['키'].var()표준편차: 분산의 루트
data.std()df['키'].std()
count(카운트)
df['키'].count()
median(중앙값)
df['키'].median()
mode(최빈값)
df['키'].mode()
피벗테이블
엑셀에서 말하는 피벗테이블과 동일하며 데이터 열 중에서 두 가지 열을 각각 행 인덱스, 열 인덱스로 사용하여 데이터를 조회하는 것을 의미한다.
- 왼쪽에 나타나는 인덱스를 행 인덱스, 상단에 나타나는 인덱스를 열 인덱스라고 부름
사용법
pd.pivot_table(df, index='소속사', columns='혈액형', values='키')
pd.pivot_table(df, index='그룹', columns='혈액형', values='브랜드평판지수', aggfunc=np.sum)
기본적으로는 평균값을 나타내고 만약 합을 구하고 싶다면 aggfunc에 값을 바꿔줄 수 있다.
groupby
- 데이터를 그룹으로 묶어 분석할 때 활용
- 성별 키의 평균과 같이 특정, 그룹별 통계 및 데이터 성질을 확인할 때 활용
groupby와 함께 활용 가능한 함수
- count()
- sum()
- mean()
- var()
- std()
- min()
- max()
사용 예시
df.groupby('그룹').mean()
df.groupby('혈액형')['키'].mean()
위처럼 특정 열만 출력도 가능하다
Multi-Index
행 인덱스를 복합적으로 구성할 수가 있다.
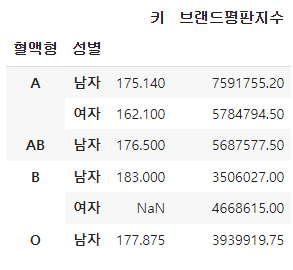
df.groupby(['혈액형', '성별']).mean()
- 혈액형으로 1차 분류 뒤에 성별로 분류
unstack
Multi-Index 형태의 DataFrame을 피벗테이블 형태로 다시 변환해 줄 수 있다.
➡️ 쫙 펼질 수 있다.
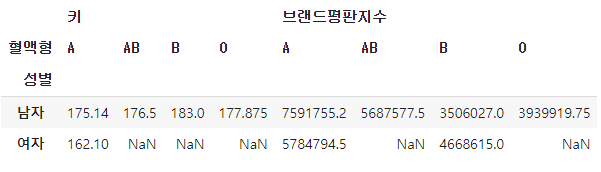
df2.unstack('혈액형')
성별, 혈액형 중 혈액형을 가장 위로 분류한다.
reset_index
df2.reset_index()
Multi-Index를 해제해서 원래 DataFrame 형태로 변환해준다.
[참조] 패스트캠퍼스 - 직장인을 위한 파이썬 데이터분석 올인원 패키지 Online.
끝!