Pandas - 전처리
[참조] 패스트캠퍼스 - 직장인을 위한 파이썬 데이터분석 올인원 패키지 Online.
결측값 채우기
데이터 분석을 하다보면 누락된 데이터가 발생할 수 있다. 누락된 데이터를 채워줄 필요가 있을 수 있고 이 때 사용하는 함수가 fillna 함수이다.
df['키'].fill(-1)
NaN으로 누락되어 있는 값을 -1로 채워넣지만 값이 유지가 되지는 않는다.
df['키'].fillna(-1, inplace=True)
inplace=True 옵션을 주면 값이 유지가 된다. 또는 채워넣은 값을 다시 대입하는 방식도 있다.
df['키'] = df['키'].fillna(-1)
누락된 값에 -1이 아닌 평균값을 넣어줄 수도 있다.
height = df['키'].mean()
df['키'].fillna(height, inplace=True)
결측값 제거
누락된 데이터를 위 방식처럼 채워줄 수도 있지만 행을 제거해버릴 수도 있다.
df.dropna()
DataFrame에서 결측값을 포함한 모든 행을 제거해버린다.
- 행 제거
df.dropna(axis=0)axis=0 옵션은 행을 드랍하는 옵션으로 기본
dropna()결과와 동일하다. - 열 제거
df.dropna(axis=1)axis=1 옵션을 주게되면 행이 아닌 열을 드랍하한 결과를 반환해준다.
how 옵션
df.dropna(how='any')
any 옵션은 하나라도 결측값이 있다면 드랍하는 옵션이다.
df.dropna(how='all')
all 옵션은 해당 행/열에 모든 값이 결측값일 경우 드랍하는 옵션이다.
중복값 제거
중복된 값을 제거해주는 함수도 존재한다.
df['키'].drop_duplicates()
drop_duplicates() 함수는 기본적으로 첫 번째 값은 유지하지만 뒤에 나온 중복된 값들을 제거해준다. NaN 값도 여러개가 있다면 중복으로 간주한다.
df['키'].drop_duplicates(keep='last')
기본적으로 첫 번째 값을 유지하기 때문에 마지막 값을 유지하기 위해서는 keep=’last’ 옵션을 준다.
df.drop_duplicates('그룹')
일반적으로 drop_duplicates() 함수는 중복된 값을 없애 NaN 값으로 만들어준다. 중복된 값이 있는 행을 드랍하기 위해서는 인자로 열 이름을 주면된다.
Drop - column/row
열 제거
df.drop('그룹', axis=1)
‘그룹’열을 제거한다.
복수 열 제거
df.drop(['그룹', '소속사'], axis=1)
복수개의 열을 제거 할떄는 list로 지정해준다.
행 제거
df.drop(3, axis=0)
3번 행을 제거한다.
복수 행 제거
df.drop([3, 5], axis=0)
복수개의 행을 제거 할때도 동일하게 list로 지정해준다.
DataFrame 합치기
행 기준 합치기
df_concat = pd.concat([df. df2], sort=False)
합칠 2개의 DataFrame을 list 형태로 지정해주고 sort=False 옵션을 주어 순서가 유지되도록 해준다. 하지만 합치게 되면 index가 꼬일 수가 있다.
df_concat.reset_index()
index를 초기화 해주게 되면 중복된 index 번호를 제거해주고 0번부터 차례대로 index 번호를 할당해 주게 된다. 하지만 ‘index’ 열을 새로 생성해서 기존 index 값을 유지해준다.
df_concat.reset_index(drop=True)
굳이 index 값을 표기해줄 이유가 없다면 drop=True 옵션을 주어 원래의 index 값을 제거해준다.
열 기준 합치기
pd.concat([df, df2], axis=1)
만약 열 기준으로 합칠때 행의 갯수가 맞지 않는다면 NaN 값을 넣어 합치게 된다.
DataFrame 병합(merge)
concat과 merge는 단순 합치는 것인지, 특정 기준에 따라 합치는 것인지에 따라 용도가 달라진다.
- concat: row나 column 기준으로 단순 합치기
- merge: 특정 고유 키 값을 기준으로 병합
pd.merge(left, right, on='기준column', how='left')
- left, right: 병합할 DataFrame
- on: 병합의 기준이 되는 column
- how: ‘left’, ‘right’, ‘inner’, ‘outer’ 병합 방식 중 한가지
pd.concat([df, df2], axis=1)
만약 이처럼 df와 df2 DataFrame을 열 기준으로 concat 합치기를 실행한다면 아래와 같은 경우가 발생할 수 있다.
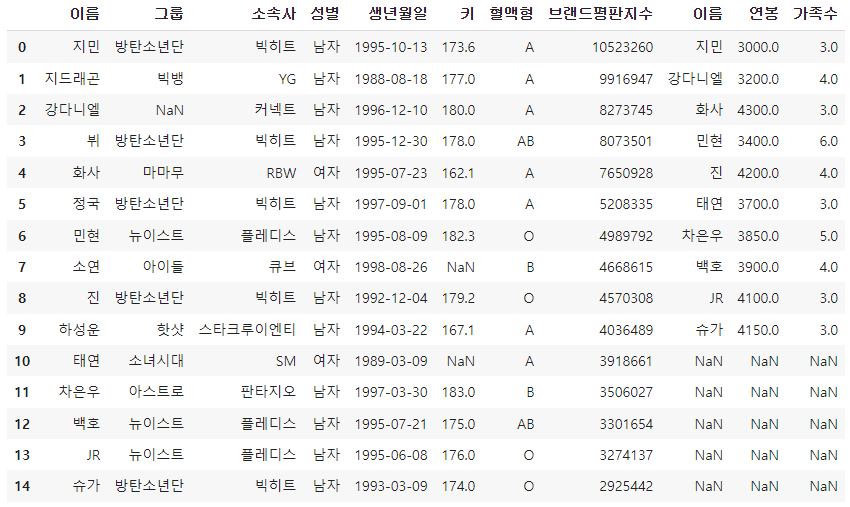
index를 기준으로 합치기 때문에 원치않는 위치에 데이터가 들어갈 수가 있다.
left
pd.merge(df, df2, on='이름', how='left')
- df와 df2를 ‘이름’에 맞추어 병합
- left: 왼쪽에 있는 df DataFrame을 기준으로 병합
- 왼쪽 DataFrame의 데이터는 유지하고 오른쪽 DataFrame에 해당 키가 없으면 NaN으로 채워넣음
right
pd.merge(df, df2, on='이름', how='right')
- left와 동일하며 기준만 오른쪽 DataFrame으로 바뀜
inner
pd.merge(df, df2, on='이름', how='inner')
- 두 DataFrame에 모두 키 값이 존재하는 경우에만 병합
- 교집합
outer
pd.merge(df, df2, on='이름', how='outer')
- 하나의 DataFrame이라도 키 값이 존재하면 병합
- 합집합
이름과 성함 같이 column 명은 다르지만 동일한 성질의 데이터를 가지고 있는 경우가 있을 수 있다. 하지만 on 옵션을 줄 때 coulmn 명은 같아야지만 merge가 가능하다.
pd.merge(df, df_right, left_on='이름', right_on='성함', how='outer')
왼쪽 DataFrame의 on 기준과 오른쪽 DataFrame의 on 기준을 설정하여 merge를 할 수 있다.
[참조] 패스트캠퍼스 - 직장인을 위한 파이썬 데이터분석 올인원 패키지 Online.
끝!