Pandas - 시각화
[참조] 패스트캠퍼스 - 직장인을 위한 파이썬 데이터분석 올인원 패키지 Online.
데이터 시각화
데이터 시각화의 목적은 수 많은 숫자와 문자형으로 된 데이터로부터 사람이 이해하기 쉽고 인사이트를 얻을 수 있는 가장 직관적인 시각적 정보를 얻기 위함이다.
EDA(Exploratory Data Analysis)
EDA란 수집한 데이터가 들어왔을 때, 이를 다양한 각도에서 관찰하고 이해하는 과정을 말한다.
plot
Colab에서는 한글 폰트가 깨지는 현상이 있기 때문에 따로 설치를 해주어야 한다.
코드 실행
!sudo apt-get install -y fonts-nanum !sudo fc-cache -fv !rm ~/.cache/matplotlib -rf import matplotlib.pyplot as plt plt.rc('font', family='NanumBarunGothic')상단 메뉴 - 런타임 - 런타임 다시 시작을 클릭
위 1번 코드 다시 한 번 실행
그래프 사이즈 키우기
plt.rcParams["figure.figsize"] = (12, 9)
그래프 형식 옵션
kind 옵션을 통해 원하는 그래프 형식을 지정할 수 있다.
- line: 선그래프
- bar: 바 그래프
- barh: 수평 바 그래프
- hist: 히스토그램
- kde: 커널 밀도 그래프
- hexbin: 고밀도 산점도 그래프
- box: 박스 플롯
- area: 면적 그래프
- pie: 파이 그래프
- scatter: 산점도 그래프
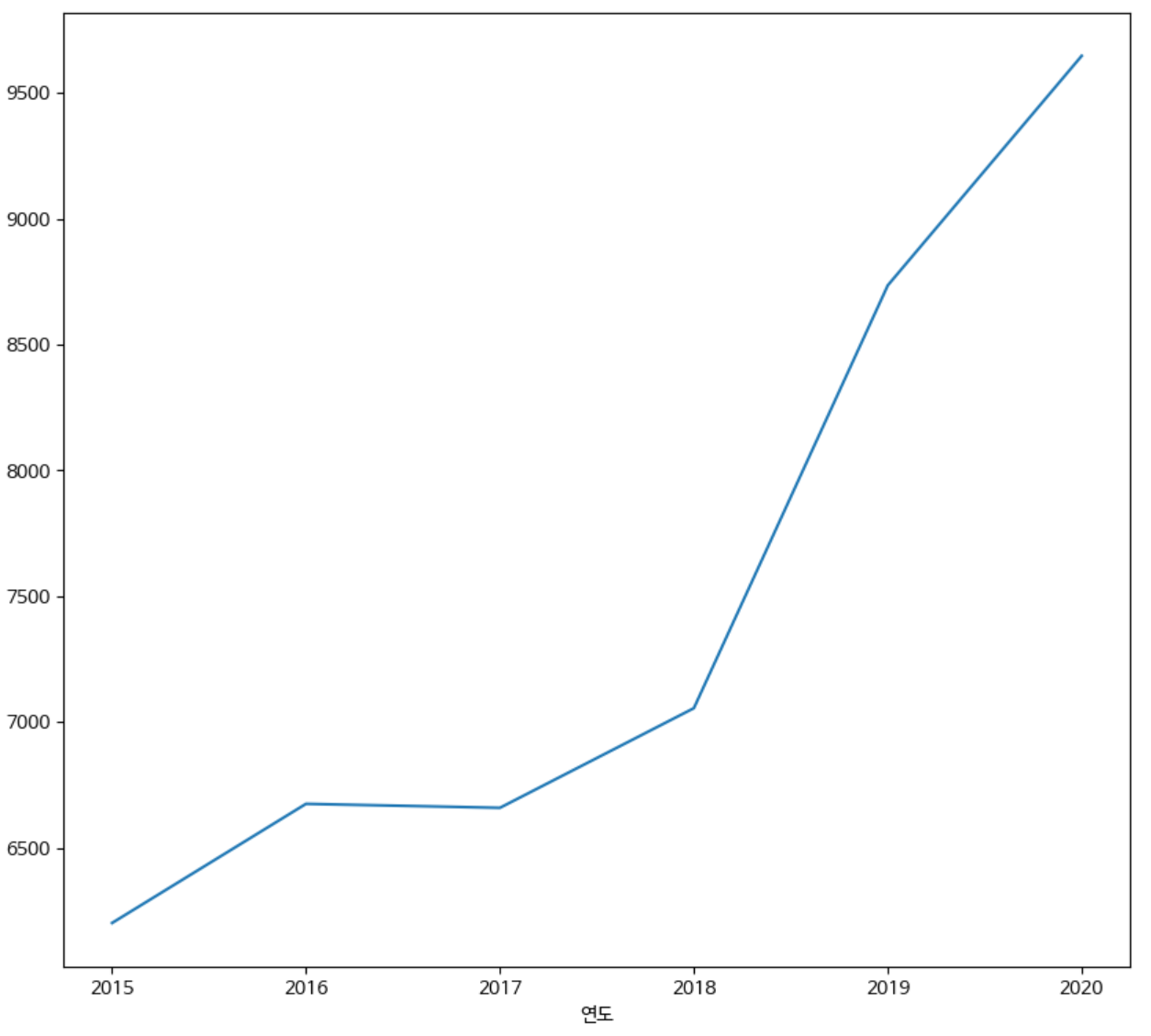
line 그래프
주가 데이터와 같이 데이터가 연속적인 경우 사용하기 적절하다.
df_seoul_year['분양가'].plot(kind='line')
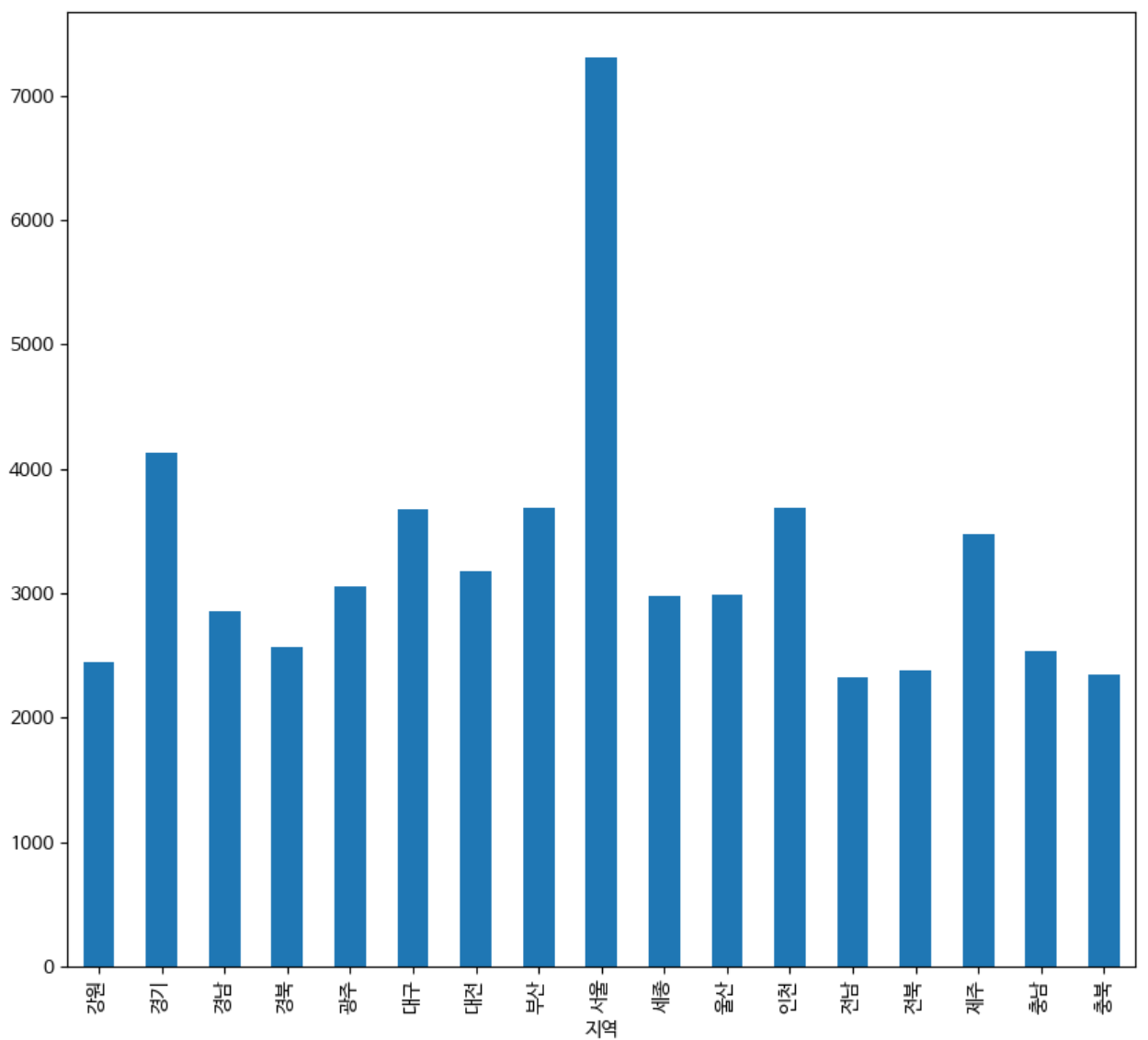
bar 그래프
그룹별로 비교할 때 유용한 그래프이다.
df.groupby('지역')['분양가'].mean().plot(kind='bar')
가로로 그리고 싶다면 bar대신에 barh를 사용하면 된다.
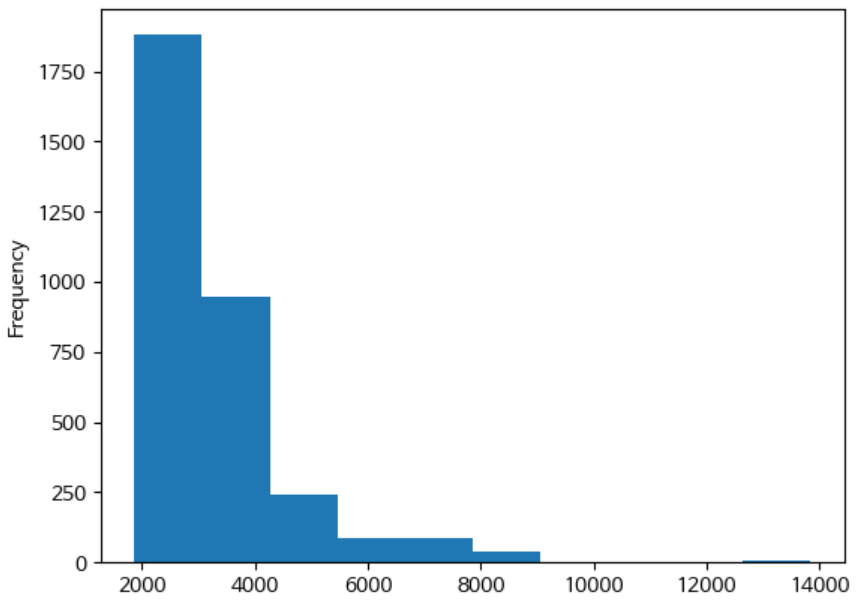
히스토그램(hist)
분포-빈도를 시각화하여 보여준다.
df['분양가'].plot(kind='hist')
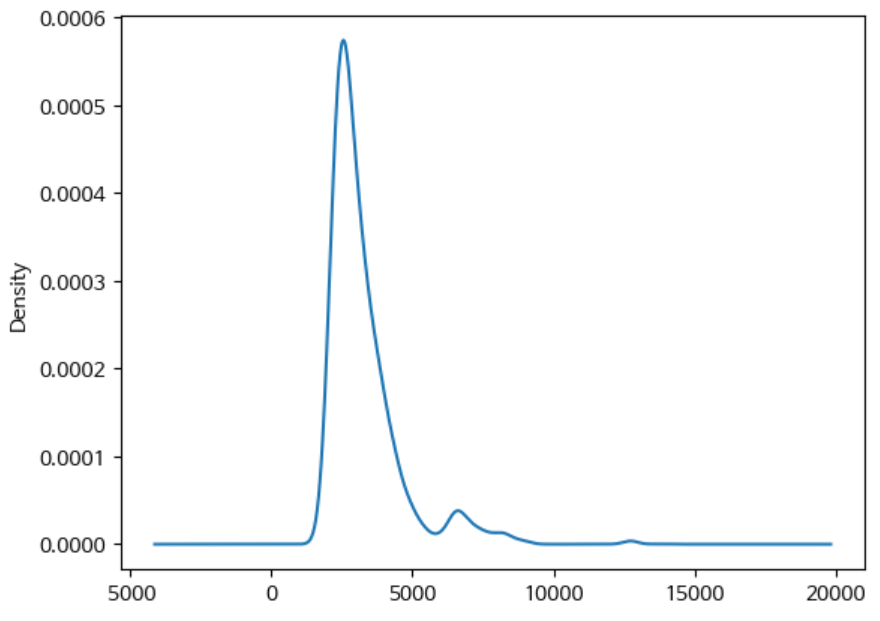
커널 밀도 그래프(kde)
히스토그램과 유사하게 밀도를 보여주는 그래프로 히스토그램과 다르게 부드러운 라인을 가지고 있다.
df['분양가'].plot(kind='kde')
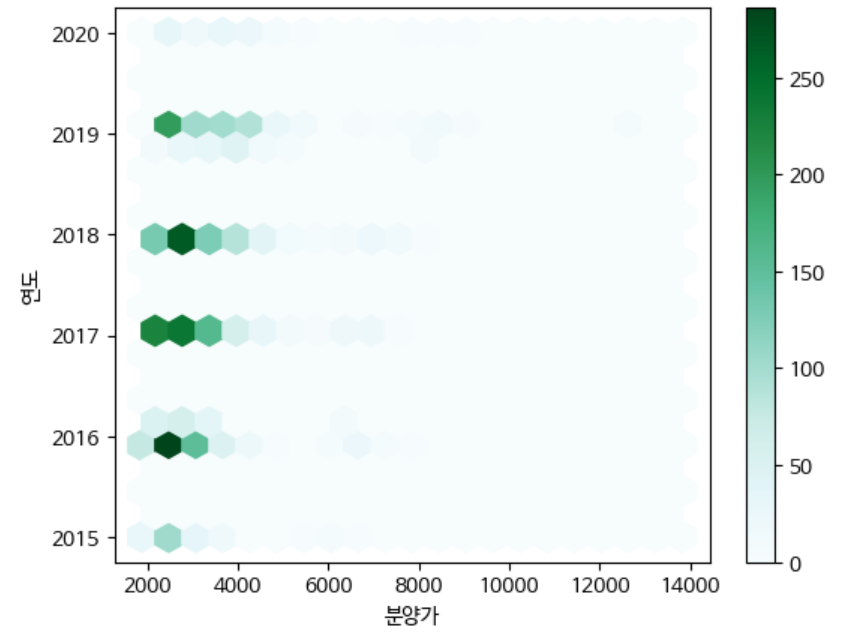
Hexbin
고밀도 산점도 그래프로 x와 y 키 값을 넣어주어야 한다. 키 값 모두 numeric 한 값을 넣어 주어야 하며 데이터의 밀도를 추정한다.
df.plot(kind='hexbin', x='분양가', y='연도', gridsize=20)
박스플롯(box)
데이터 outlier(이상치)를 감지할 때 또는 분위 값을 활용하는 용도로 많이 활용되는 그래프이다.
df_seoul = df.loc[df['지역'] == '서울']
df_seoul['분양가'].plot(kind='box')
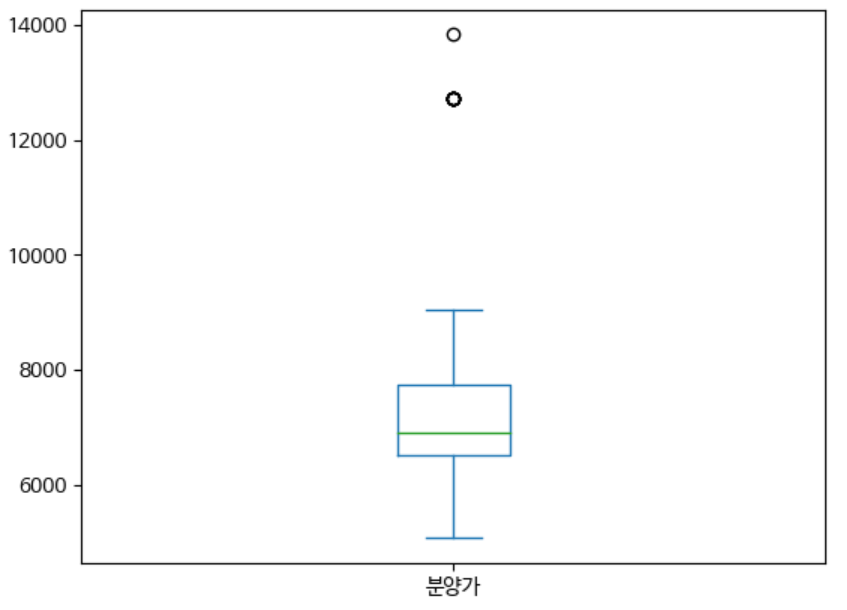
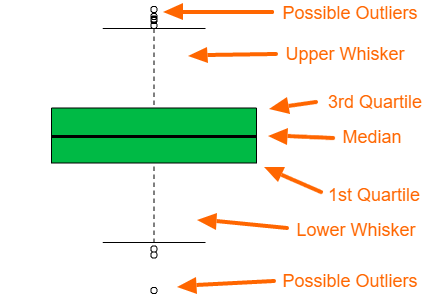
범위에 벗어난 동그란 점들을 outlier라고 한다. 범위를 구하려면 먼저 IQR(Inter Quantile Range)를 구해야한다. \[IQR = (7732 - 6519.75) * 1.5\]
IQR을 이용해 박스 플롯의 최댓값과 최솟값을 구할 수가 있고 이 범위에 벗어난 값들이 outlier이다. \[Box_{max} = Box_{75\%} + IQR\] \[Box_{min} = Box_{25\%} - IQR\]
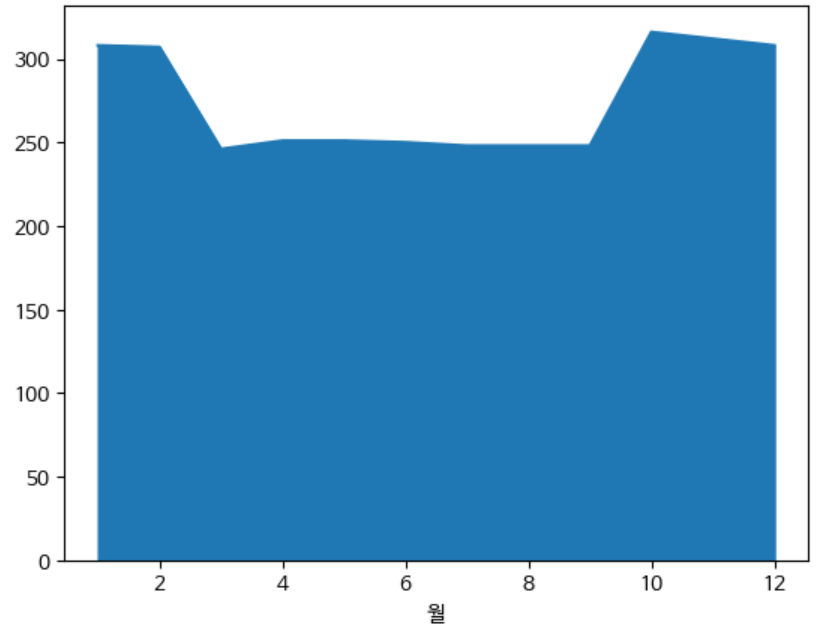
area plot
area plot은 line 그래프의 아래 영역을 색칠해 준다.
df.groupby('월')['분양가'].count().plot(kind='line')
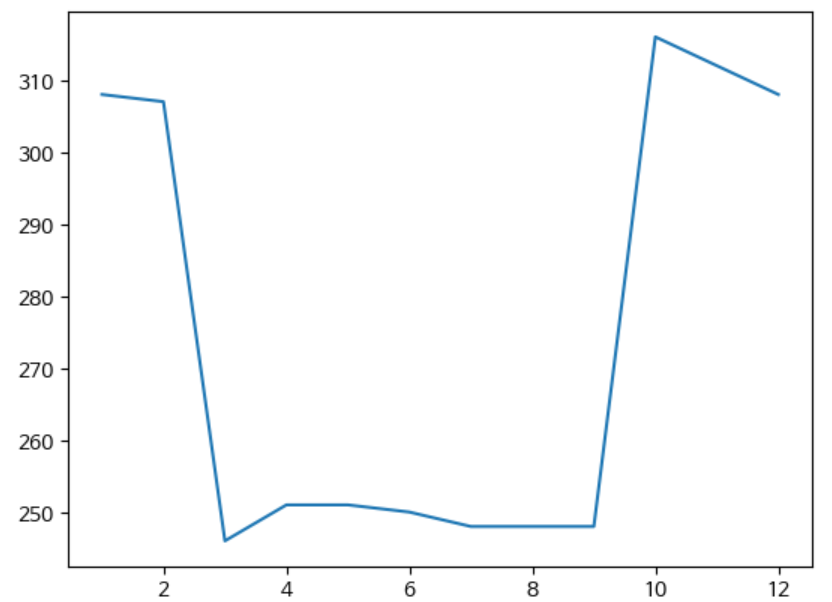
위 그래프는 line 그래프를 보여주고 있고 아래 area plot을 보면 색칠이 된 결과를 볼 수 있다.
df.groupby('월')['분양가'].count().plot(kind='area')
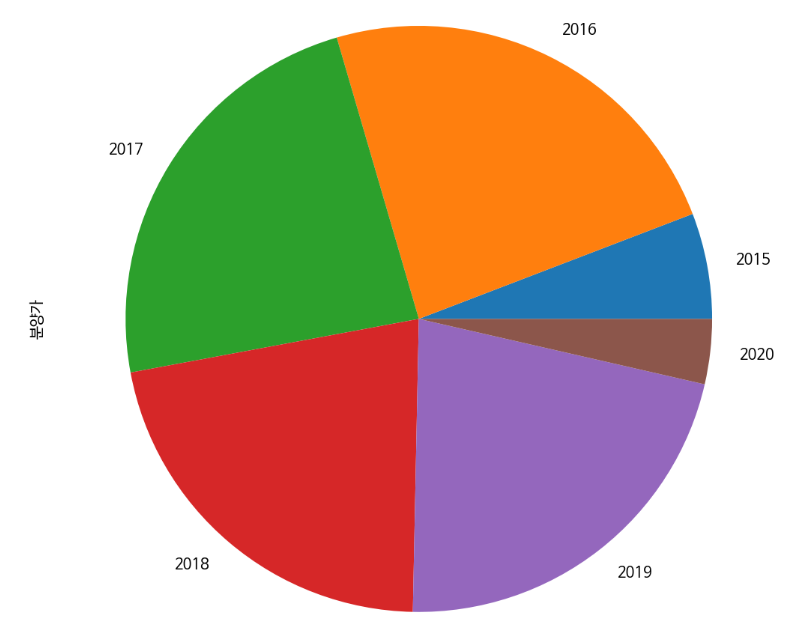
파이 그래프(pie)
데이터의 점유율을 보여줄 때 유용하게 사용된다.
df.groupby('연도')['분양가'].count().plot(kind='pie')
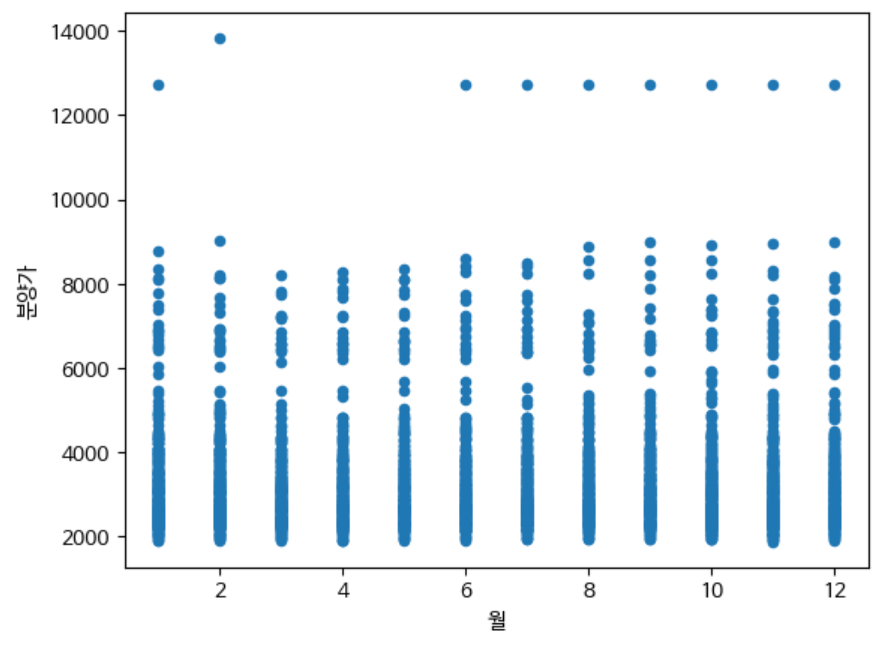
산점도 그래프(scatter)
데이터를 점으로 표기해주며 hexbin과 유사하게 numeric한 x, y 값에 따른 데이터 분포도를 확인할 수 있다.
df.plot(x='월', y='분양가', kind='scatter')
[참조] 패스트캠퍼스 - 직장인을 위한 파이썬 데이터분석 올인원 패키지 Online.
끝!