분류(Classification) 2
[참조] 패스트캠퍼스 - 직장인을 위한 파이썬 데이터분석 올인원 패키지 Online.
- 최근접 이웃 알고리즘(KNeighborsClassifier)
- 서포트 벡터 머신(SVC)
- 의사 결정 나무(Decision Tree)
- 분류 정확도의 함정
- 오차 행렬
- 정밀도(precision)
- 재현율(recall)
- f1 score
최근접 이웃 알고리즘(KNeighborsClassifier)
최근접 이웃 알고리즘은 K-NN 알고리즘이라고도 하며 주변에서 가장 가까은 K개의 데이터를 보고 데이터가 속할 그룹을 판단하는 알고리즘이다. 비슷한 특성을 가진 데이터는 비슷한 범주에 속하는 경향이 있다는 가정하에 적용한다.
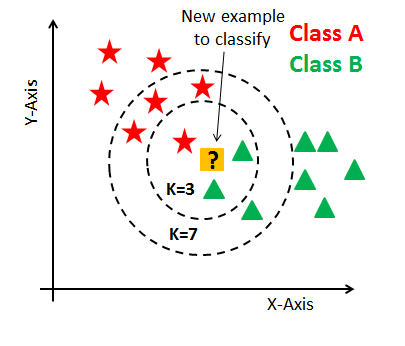
- K=3일 때 ?는 Class B로 구분
- K=7일 때 ?는 Class A로 구분
위 그림과 같이 K의 값에 따라 분류 성능이 좌지우지 될 것이다.
K-NN 모델 로드
from sklearn.neighbors import KNeighborsClassifier
모델 선언
knc = KNeighborsClassifier()
모델 학습
knc.fit(x_train, y_train)
예측
knc_pred = knc.predict(x_valid)
모델 평가
(knc_pred == y_valid).mean()
서포트 벡터 머신(SVC)
SVC 모델은 새로운 데이터가 어느 그룹에 속할지 판단하는 미진 선형 분류 모델로 경계로 표현되는 데이터들 중 가장 큰 폭을 가진 경계를 찾는 알고리즘이다.

위 그림과 같이 마진이 가장 큰 모델을 찾는 것이라고 볼 수 있다. 이진 분류이기 때문에 분류의 개수가 많아지면 OvR 전략을 사용한다.
SVC 모델 로드
from sklearn.svm import SVC
모델 학습
svc = SVC()
svc.fit(x_train, y_train)
svc_pred = svc.predict(x_valid)
모델 평가
(svc_pred == y_valid).mean()
분류 결과
svc_pred[:5]
각 클래스 별 확률값
svc.decision_function(x_valid)[:5]
의사 결정 나무(Decision Tree)
의사 결정 나무 모델은 스무고개처럼 나무 가지치기를 통해 소그룹으로 나누어 판별하는 알고리즘이다.

모델 로드
from sklearn.tree import DecisionTreeClassifier
모델 학습
dtc = DecisionTreeClassifier()
dtc.fit(x_train, y_train)
dtc_pred = dtc.predict(x_valid)
모델 평가
(dtc_pred == y_valid).mean()
시각화 모듈 로드
from sklearn.tree import export_graphviz
from subprocess import call
그래프 시각화
def graph_tree(model):
# .dot 파일로 export 해줍니다
export_graphviz(model, out_file='tree.dot')
# 생성된 .dot 파일을 .png로 변환
call(['dot', '-Tpng', 'tree.dot', '-o', 'decistion-tree.png', '-Gdpi=600'])
# .png 출력
return Image(filename = 'decistion-tree.png', width=500)
graph_tree(dtc)
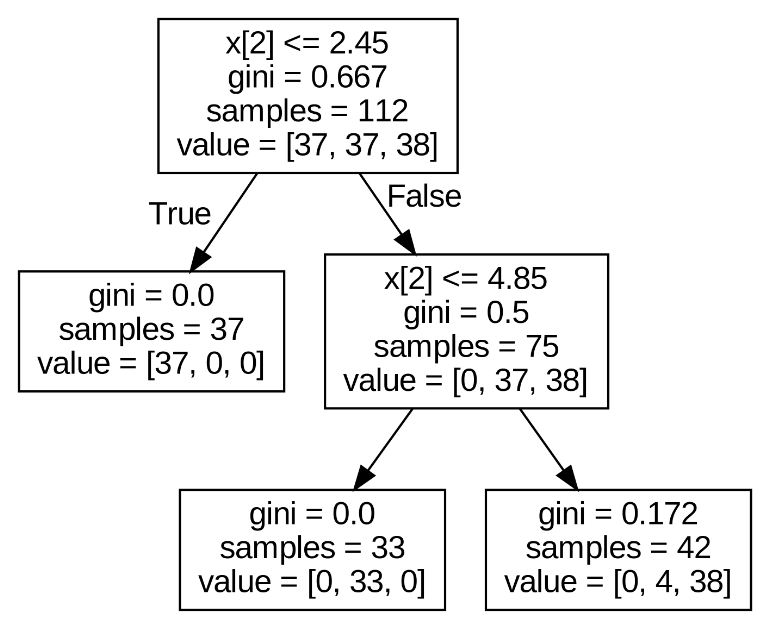
- gini계수: 불순도를 의미하며 계수가 높을 수록 엔트로피가 커 혼잡하게 섞여 있다는 의미
- max_depth: 과적합을 막기 위해 뎁스를 줄일 수 있음
dtc = DecisionTreeClassifier(max_depth=2)
분류 정확도의 함정
유방암 환자 데이터셋 로드
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
import numpy as np
데이터 프레임 생성
cancer = load_breast_cancer()
data = cancer['data']
target = cancer['target']
feature_names=cancer['feature_names']
df = pd.DataFrame(data=data, columns=feature_names)
df['target'] = cancer['target']
샘플 생성
pos = df.loc[df['target']==1]
neg = df.loc[df['target']==0]
- target
- 0: 악성종양
- 1: 음성종양
x_train, x_test, y_train, y_test = train_test_split(sample.drop('target', 1), sample['target'], random_state=42)
모델 학습
model = LogisticRegression()
model.fit(x_train, y_train)
pred = model.predict(x_test)
모델 평가
(pred == y_test).mean()
결과는 97.8%정도가 나온다.
0.978021978021978
악성일 확률은 양성일 확률보다 훨씬 적기 때문에 만약 모든 데이터가 양성이라고 설정하고 예측 해보도록 한다.
my_prediction = np.ones(shape=y_test.shape)
(my_prediction == y_test).mean()
결과는 오히려 정확도가 더 높다는 것을 확인할 수 있다. 즉, 굳이 머신러닝으로 학습시킨 것보다 무조건 양성이라고 판단한 것이 오히려 정확도가 높다는 것이다.
0.989010989010989
그렇다면 정확도만 보고 정확도가 98.9%인 의사가 97.8% 정확도의 의사보다 더 뛰어난 것인가? 정확도만 보고 분류기의 성능을 판단하는 것은 이와 같은 오류에 빠지게 될 수 있다.
오차 행렬
오차 행렬 로드
from sklearn.metrics import confusion_matrix
matrix 생성 및 시각화
confusion_matrix(y_test, pred)
sns.heatmap(confusion_matrix(y_test, pred), annot=True, cmap='Reds', )
plt.xlabel('Predict')
plt.ylabel('Actual')
plt.show()
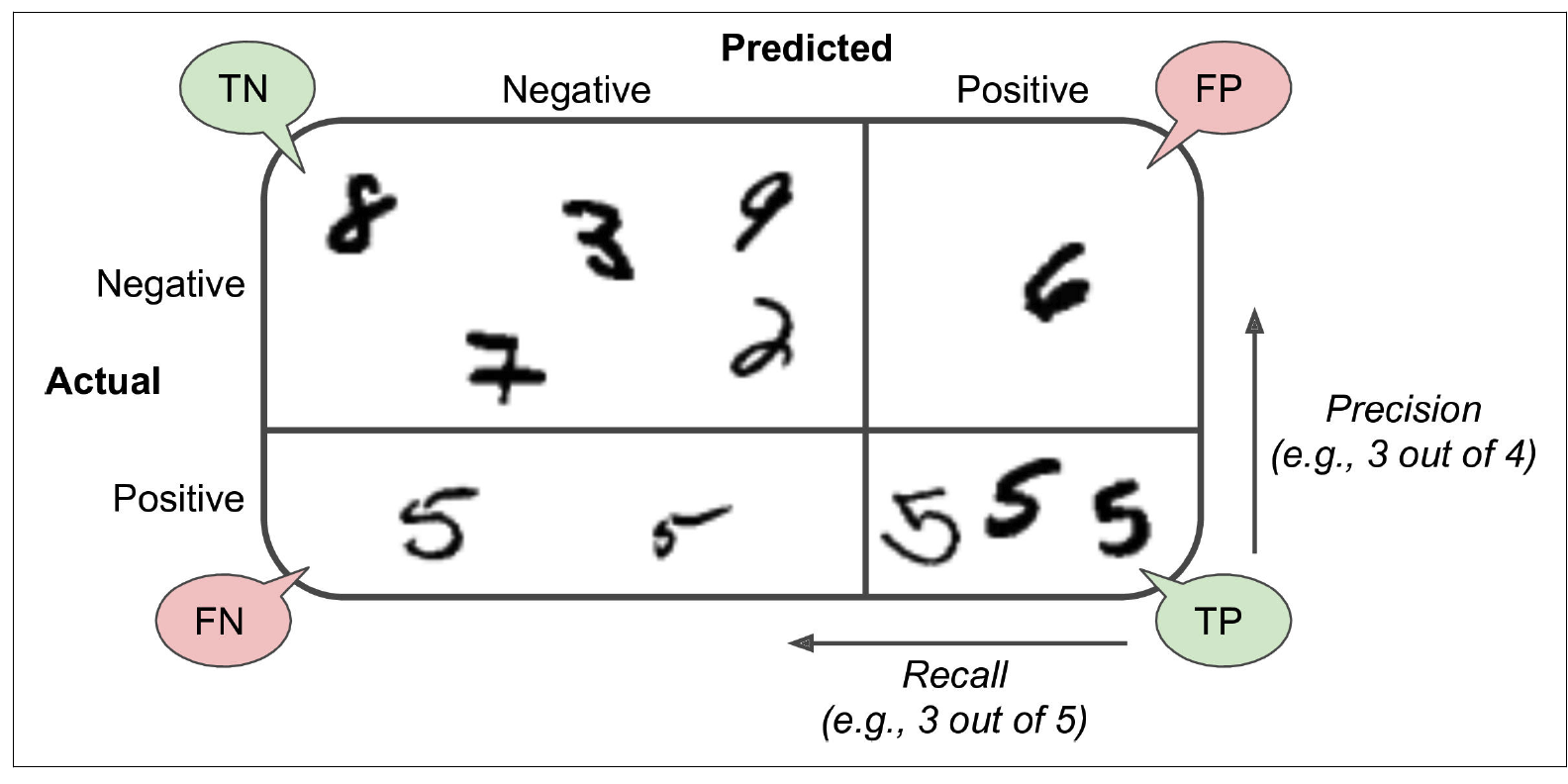
위 그림처럼 4가지(TN, FN, TP, FP)로 분류하고 틀린 비율 등을 확인해 보면서 성능을 확인할 수 있다.
정밀도(precision)
필요 모듈 로드
from sklearn.metrics import precision_score, recall_score
양성 예측 정확도 \[\frac{TP}{TP + FP}\]
위 계산식을 sklearn에서 함수로 제공한다.
precision_score(y_test. pred)
하지만 무조건 양성으로 판단하면 좋은 정밀도를 얻기 떄문에 유용하지 않다.
재현율(recall)
재현율은 정확하게 감지한 양성 샘플 비율을 말하며 민감도(sensitivity) 또는 TPR(True Positive Rate)라고도 부른다. \[\frac{TP}{TP + FP}\]
recall_score(y_test, pred)
f1 score
f1 score는 정밀도와 재현율의 조화 평균을 나타내는 지표이다. \[2*\frac{정밀도 * 재현율}{정밀도 + 재현율}=\frac{TP}{TP+\frac{FN+FP}{2}}\]
[참조] 패스트캠퍼스 - 직장인을 위한 파이썬 데이터분석 올인원 패키지 Online.
끝!