회귀(Regression) - 성능 평가
[참조] 패스트캠퍼스 - 직장인을 위한 파이썬 데이터분석 올인원 패키지 Online.
보스턴 주택 가격 데이터셋
데이터셋 로드
from sklearn.datasets import load_boston
data = load_boston()
DataFrame 생성
df = pd.DataFrame(data['data'], columns=data['feature_names'])
df['MEDV'] = data['target']
MEDV(자가 주택의 중앙값)을 Target으로 설정한다.
train/test 데이터 분할
x_train, x_test, y_train, y_test = train_test_split(df.drop('MEDV', 1), df['MEDV'])
평가 지표
MSE(Mean Squared Error) \[{(\frac{1}{n})\sum_{i=1}^{n}(y_{i} - x_{i})^{2}}\]
예측값과 실제값의 차이에 대한 제곱의 평균을 낸 값을 의미한다.
pred = np.array([3, 4, 5])
actual = np.array([1, 2, 3])
def my_mse(pred, actual):
return ((pred - actual)**2).mean()
sklearn에서 제공되는 함수를 사용할 수도 있다.
from sklearn.metrics import mean_squared_error
mean_squared_error(pred, actual)
MAE(Mean Absolute Error) \[(\frac{1}{n})\sum_{i=1}^{n}\left | y_{i} - x_{i} \right |\]
예측값과 실제값의 차이에 대한 절대값의 평균울 낸 값을 의미한다.
def my_mae(pred, actual):
return np.abs(pred - actual).mean()
sklearn에서 제공되는 함수를 사용할 수도 있다.
from sklearn.metrics import mean_absolute_error
mean_absolute_error(pred, actual)
RMSE(Root Mean Squared Error) \[\sqrt{(\frac{1}{n})\sum_{i=1}^{n}(y_{i} - x_{i})^{2}}\]
예측값과 실제값의 차이에 대한 제곱의 평균을 낸 뒤 루트를 씌운 값을 말한다.
def my_rmse(pred, actual):
return np.sqrt(my_mse(pred, actual))
from sklearn.metrics import mean_squared_error
np.sqrt(mean_squared_error(pred, actual))
성능평가를 위한 함수
라이브러리 로드 및 선언
import matplotlib.pyplot as plt
import seaborn as sns
my_predictions = {}
colors = ['r', 'c', 'm', 'y', 'k', 'khaki', 'teal', 'orchid', 'sandybrown',
'greenyellow', 'dodgerblue', 'deepskyblue', 'rosybrown', 'firebrick',
'deeppink', 'crimson', 'salmon', 'darkred', 'olivedrab', 'olive',
'forestgreen', 'royalblue', 'indigo', 'navy', 'mediumpurple', 'chocolate',
'gold', 'darkorange', 'seagreen', 'turquoise', 'steelblue', 'slategray',
'peru', 'midnightblue', 'slateblue', 'dimgray', 'cadetblue', 'tomato'
]
성능평가 시각화 함수
def plot_predictions(name_, pred, actual):
df = pd.DataFrame({'prediction': pred, 'actual': y_test})
df = df.sort_values(by='actual').reset_index(drop=True)
plt.figure(figsize=(12, 9))
plt.scatter(df.index, df['prediction'], marker='x', color='r')
plt.scatter(df.index, df['actual'], alpha=0.7, marker='o', color='black')
plt.title(name_, fontsize=15)
plt.legend(['prediction', 'actual'], fontsize=12)
plt.show()
학습 모델 성능 평가 함수
def mse_eval(name_, pred, actual):
global predictions
global colors
plot_predictions(name_, pred, actual)
mse = mean_squared_error(pred, actual)
my_predictions[name_] = mse
y_value = sorted(my_predictions.items(), key=lambda x: x[1], reverse=True)
df = pd.DataFrame(y_value, columns=['model', 'mse'])
print(df)
min_ = df['mse'].min() - 10
max_ = df['mse'].max() + 10
length = len(df)
plt.figure(figsize=(10, length))
ax = plt.subplot()
ax.set_yticks(np.arange(len(df)))
ax.set_yticklabels(df['model'], fontsize=15)
bars = ax.barh(np.arange(len(df)), df['mse'])
for i, v in enumerate(df['mse']):
idx = np.random.choice(len(colors))
bars[i].set_color(colors[idx])
ax.text(v + 2, i, str(round(v, 3)), color='k', fontsize=15, fontweight='bold')
plt.title('MSE Error', fontsize=18)
plt.xlim(min_, max_)
plt.show()
모델 제거 함수
def remove_model(name_):
global my_predictions
try:
del my_predictions[name_]
except KeyError:
return False
return True
LinearRegression
LinearRegression 모델 로드
from sklearn.linear_model import LinearRegression
model = LinearRegression(n_jobs=-1)
- n_jobs: CPU 사용 개수로
-1은 모든 CPU를 사용하겠다는 의미
학습 및 예측
model.fit(x_train, y_train)
pred = model.predict(x_test)
성능 평가
mse_eval('LinearRegression', pred, y_test)
위에서 만든 함수로 실행한다.
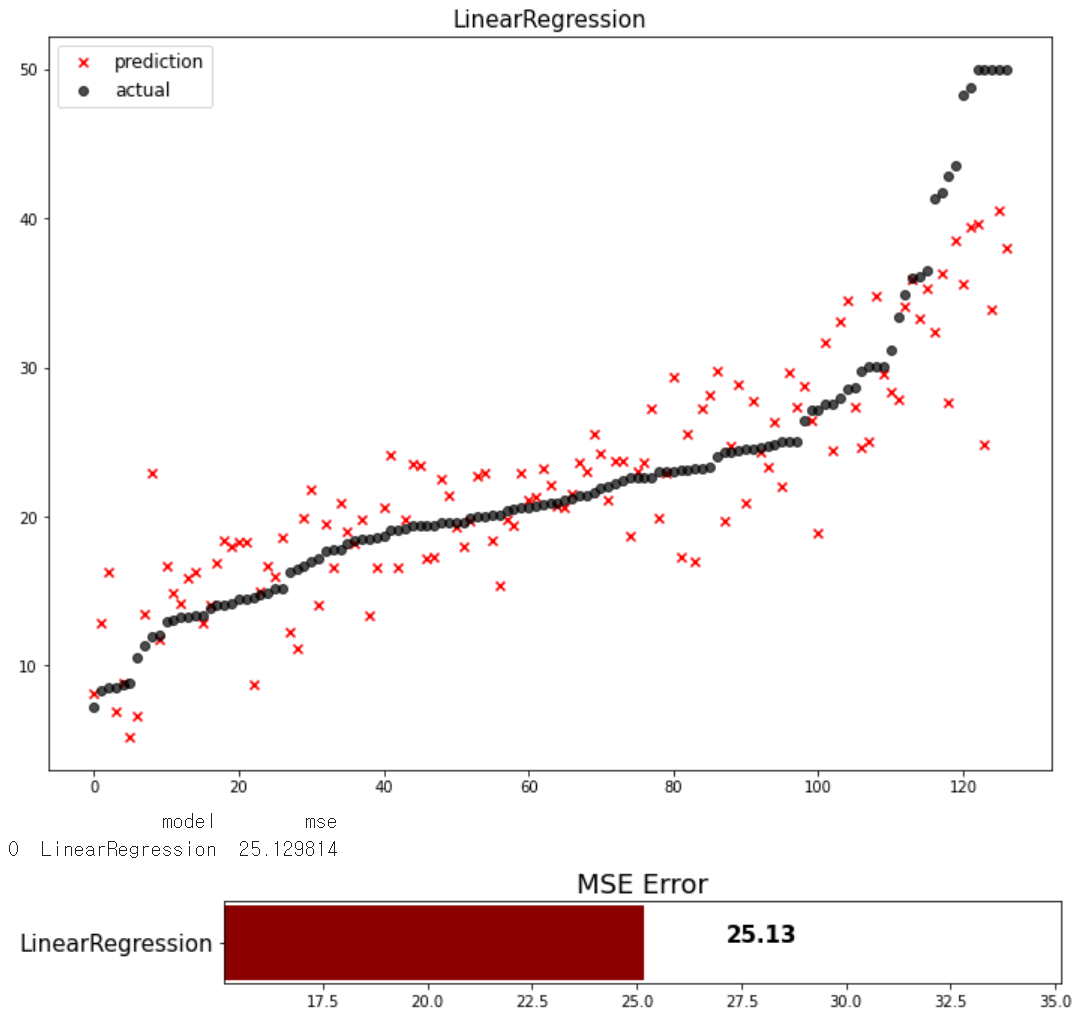
예측값이 얼마나 오차가 있는지 시각화하여 보여주게된다.
[참조] 패스트캠퍼스 - 직장인을 위한 파이썬 데이터분석 올인원 패키지 Online.
끝!