Generating Holistic 3D Human Motion from Speech
CVPR 2023 - Generating Holistic 3D Human Motion from Speech 논문 정리
Abstract
해당 논문은 사람의 음성으로부터 3D 신체 움직임을 생성하는 Talk SHOW(Talk Synchronous HOlistic body in the Wild) 라는 솔루션에 대해 설명을 하는 논문이다
- Input: 사람의 음성 녹음
- Output: 3D 신체 포즈, 손 동작, 얼굴 표정 시퀀스 합성
SHOW에서는 신체별로 분리된 모델링을 하는데 얼굴 관절은 사람의 음성과 강한 상관관계가 있지만 몸의 포즈와 손 제스처는 상관관계가 낮기 때문이다.
![]()
Talk SHOW 링크: https://talkshow.is.tue.mpg.de/
Introduction
최근 사람의 말에서 신체 동작으로 모델링을 하는 방법이 빠르게 발전하고 있다. 이는 크게 규칙 기반(rule-based) 과 학습 기반(learning-based) 방법으로 나눌 수 있으며 일반적으로 얼굴/상체 3D mesh 2D/3D 관절이 있는 얼굴 형태 표현한다.
본 논문에서는 더 나은 상호작용을 위해 음성에 맞춰 몸, 손, 얼굴 표정을 함꼐 사용하여 의사소통한다.
한계점
- 전체 몸의 3D mesh와 동기화 된 음성 녹음 데이터 셋 부족
→ 동기화된 오디오가 포함된 In the wild (일반적인 환경에서 촬영된) 동영상 데이터 사용 - 사람마다 얼굴, 손 모양 이 다르고 변형이 심함
→ 정확한 전체 몸 mesh를 가져오기 위해 신체에 따라 형태, 포즈 등 여러 부분을 캡처
→ SMPLify-X 모델 사용 - 신체 부위마다 음성 신호와의 상관관계가 다름
→ 3D 신체 동작, 손짓, 얼굴 표정을 사실적이고 자동 회귀적으로 합성해주는 TalkSHOW 제안
Related work
Holistic Body Reconstruction
본 논문과 비슷한 주제에 대해 조사한 결과를 설명한다.
- SMPLify-X: off-the-shelf detectors(객체 검출기)를 통해 얻은 2D 키포인트에 SMPL-X 모델 적용
- PIXIE: part specific feature의 정확성을 추정하는 moderators를 사용해 SMPL-X 파라미터를 직접 회귀하는 방법
- PyMAF-X: spatial alignment attention로 몸과 손의 위치를 정확하게 파악

Speech-to-Motion Datasets
기존 데이터셋은 크게 2가지로 나눌 수 있다.
- In-house: 제한된 환경에서 촬영된 데이터로 정확한 annotaion을 통해 얼굴 또는 몸의 위치를 파악할 수 있지만 비용, 공수에 따라 규모가 제한적이다.
- In-the-wild: 일반적인 환경에서 촬영된 데이터로 해당 논문에서 사용되는 데이터셋이다. p-GT(psuedo ground truth)가 annotation으로 사용된다.
Holistic Body Motion Generation from Speech
음성을 통한 신체 동작을 생성하는 방법은 얼굴, 손, 몸 3가지 신체 부위 동작으로 구성이 되며 두 가지 방식으로 구분할 수 있다.
- 규칙 기반(rule-based):
- 사전에 신체 동작에 대해 “Units”로 미리 정의를 해두고 정의된 동작과 매핑하는 방식
- 설명과 제어가 가능하지만 복잡하고 사실적인 동작 패턴을 생성하려면 많은 비용이 듬
- 학습 기반(learning-based):
- 학습을 시킨 방식으로 기존의 알고리즘은 신체 일부분만 고려한 학습이고 신체 전체를 고려하지 않았기 때문에 한계가 있음
- 본 논문에서는 cross-conditional autoregressive 모델로 다른 신체간 상호 의존성과 이전 동작 등을 고려한 모델 사용
Dataset
해당 논문에서는 30fps의 3D 전신 mesh와 22K sample rate로 동기화 된 오디오로 구성된 데이터 셋을 사용한다.
Dataset Description
이 데이터셋은 다양한 화법 스타일을 가진 사람들의 실제 대화 동영상을 기반의 데이터이며 저해상도, 손이 가려지거나 다운로드 링크가 잘못된 경우를 수동으로 필터링되었다.
- 오디오 데이터: 26.9시간의 대규모 데이터셋이기 때문에 mini-batch processing 처리를 위해 10초 미만의 클립형태로 크롭되었다.
- 3d 전신 mesh 데이터: SHOW로 추출한 3d body mesh로 얼굴, 손, 몸통이 연결된 방식이며 p-GT annotation에 사용된다.
\(T\) 프레임에 따른 p-GT 컴포넌트
- Body shape: \(\beta \in \mathbb{R}^{300}\)
- Body pose: \(\{\theta_t \| \theta_t \in \mathbb{R}^{156}\}^T_{t=1}\)
- Camera pose: \(\theta^c \in \mathbb{R}^{3}\)
- Translation: \(\epsilon \in \mathbb{R}^{3}\)
- Facial expression: \(\{\Psi_t \| \Psi_t\ \in \mathbb{R}^{100}\}^T_{t=1}\)
- Jaw pose: \(\theta^{jaw}_t \in \mathbb{R}^3\)
- Body pose: \(\theta^b_t \in \mathbb{R}^{63}\)
- Hand pose: \(\theta^h_t \in \mathbb{R}^{90}\)
Good Practices for Improving p-GT
- 정확한 3d body mesh 추정을 위해 p-GT를 좀 더 개선 시키려는 것
- SMPLify-X 초기화를 통해 SMPLify-X의 성능을 최적화, 가속화, 안정화 시킬 수 있음
- 입력된 이미지와 OnePose에서 예측한 관절 간 차이를 최적화하여 오차를 최소화
- 비현실적으로 몸체가 재구성되는 것을 방지하기 위해 정규화가 사용되어 3d body mesh가 자연스러운 형태를 유지하도록 함
Method
Preliminary
\(M = \{m\}^T_t\) 은 전체 모션 시퀀스이며 얼굴, 몸, 손 동작을 각각 \(M^f\), \(M^b\), \(M^h\) 라고 나타낸다.
Face Generator
오디오 신호 \(A_{1:T}\)가 주어졌을 때 모델이 실제 유사한 표정 동작의 벡터 시퀀스 \(\hat{M}^f_{1:T}\)를 생성하는 것을 목표로 한다.
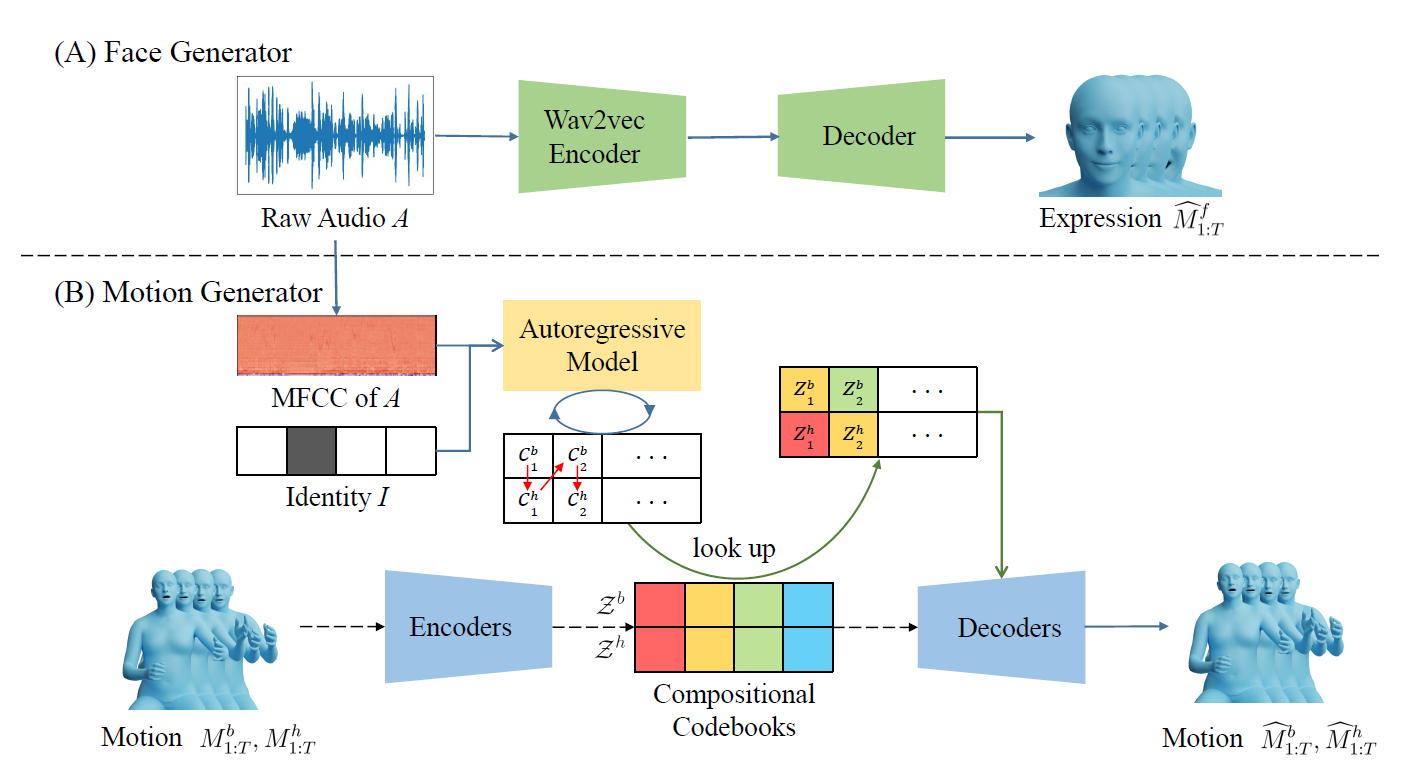
(A) Face Generator
- Encoder:
- Wav2vec Encoder를 사용하여 입력 오디오 신호를 768차원에서 256차원으로 축소
- Decoder:
- 축소된 차원 음성을 받아 6 레이어의 TCNs(Temporal Convolutional Networks)에서 시계열 데이터 처리
- 얼굴 표정 동작이 담긴 \(\hat{M}^f_{1:T}\) 얼굴 표정 동작 벡터 시퀀스 반환
Body and Hand Generator
VQ-VAE를 활용하여 multi-mode distribution space를 학습한다. multi-mode distribution space라는 것은 여러 개의 모드를 가진 확률 분포 공간을 말하며 여러 가능성의 결과를 도출해 내는 것을 말한다.
- 오디오 신호처리
- 64차원 MFCC features를 사용
- 말하는 사람의 스타일을 정의하기 위해 one-hot vector 사용
- Encoder:
- 몸과 손의 움직임을 입력받아 Compositional Codebooks로 discrete한 모션 정보 전달
- 몸, 손 움직임을 각각 따로 인코딩하여 Sub-codebook 인덱스로 변환
- Compositional Codebooks:
- VQ-VAE 사용
- Encoder로부터 받은 모션 정보를 조합하여 다양한 모션 생성
- Cross-Conditional Autoregressive Modeling:
- 오디오, 모션 스타일, 몸 움직임, 손 움직임을 입력데이터로 사용
- 이전의 입력 데이터를 반영해 예측
- Decoder:
- codebook 인덱스를 움직임으로 변환
- 몸, 손, 얼굴 움직임을 모두 연결하여 하나의 비디오 클립 구성
Experiments
데이터셋은 다음과 같이 분할한다.
- 훈련: 80%
- 평가: 10%
- 테스트: 10%
Quantitative Analysis
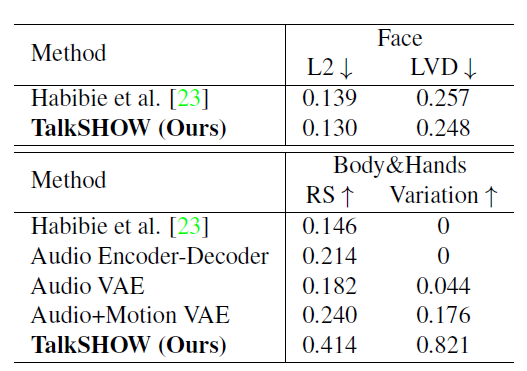
- L2: 실제 얼굴의 위치와 생성된 얼굴 위치 간의 거리
- LVD: 실제 얼굴의 위치와 생성된 얼굴 위치 간의 속도 차이
- RS: 생성된 모션의 실제성을 평가하는 지표
- Variation: 생성된 모션의 다양성을 평가하는 지표
Qualitative Analysis

- 같은 말이라도 음성 강조에 따라 다른 모션 생성
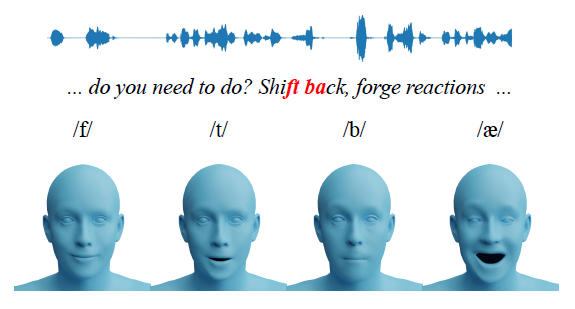
- 정확한 입술 모양 생성
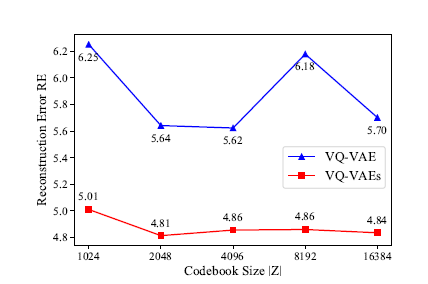
- 단일 codebook보다는 다양한 codebook을 사용할 수록 RE(Reconstruction Error)가 낮아져 효과적임
Perceptual Study
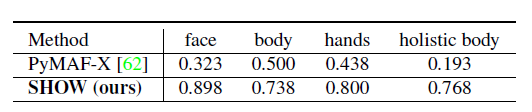
- 10명의 참가자 대상으로 Reconstruction 성능 평가를 했을떄 생성된 모델과 비디오 일치 여부 Yes/No로 평가한 결과

- A/B 테스트를 진행한 결과 Habibie를 가장 선호함