StyleGAN-nada
카테고리 : TIL (Tody I Learned) >> Papers
Abstract
StyleGAN-nada는 CLIP(Constrastive-Languate-Image-Pretraining) 모델을 활용한 생성형 AI 모델로 새로운 도메인으로의 전환이 가능하다. 새로운 도메인으로 전환함으로써 이미지를 다양한 스타일의 새로운 이미지로 생성이 가능해진다.

Related work
Text-guided synthesis
- 언어 기반으로 한 이미지 검색, 이미지 캡션 생성 등의 작업 포함
- CLIP 모델이 해당
- 4억 개의 텍스트-이미지 Pair 데이터 학습
- 인코더로 임베딩 후 같은 Pair에 대해는 거리를 가깝게, 다른 Pair에 대해서는 거리가 멀어지도록 학습
- 이미지와 텍스트를 같은 임베딩 공간으로 매핑하여 유사성을 계산
Training generators with limited data
- 수 백/천 개 정도의 제한된 이미지로 데이터 분포를 모방하는 것이 목표
- 데이터 증강을 통해 데이터를 늘려 학습
- 데이터를 더 잘 학습시킬 수 있도록 auxiliary task 도입
- 전이학습 수행
Preliminaries
StyleGAN
- Mappning Network: 잠재 코드 \(z\) 를 학습된 잠재 공간 \(W\)의 벡터 \(w\)로 변환
- \(z\): 가우시안 분포에서 샘플링된 잠재 공간 \(Z\)의 벡터
- \(W\): Mapping Network를 거친 \(w\) 벡터가 위치하며 이미 있는 특성 학습
- Synthesis Network: 매핑 네트워크를 거진 \(w\) 벡터가 합성 네트워크에 입력되어 최종 이미지 생성
StyleCLIP
- DirectLatent Code Optimization
- CLIP을 통해 StyleGAN이 생성한 이미지의 임베딩 벡터와 목표 텍스트 임베딩 벡터를 획득
- 이미지 임베딩 벡터와 텍스트 임베딩 벡터 간 거리를 최소화
- ex) 웃고 있는 남자 이미지 + “울고 있는 사람” => 울고 있는 남자 이미지
- Training an Encoder/Mapper
- 여러 잠재 코드와 이미지, 텍스트 설명 수집
- Encoder와 Mapper를 학습시켜 잠재 코드 수정
- Discovering Global Directions
- CLIP을 사용하여 잠재 공간에서 변화의 글로벌 방향 계산
- 두 텍스트 임베딩 벡터 간의 차이를 계산하여 잠재 공간에서 변화 방향 계산
- ex) “짧은 머리 사람”, “긴 머리 사람” 두 텍스트 임베딩 벡터 간 차이를 계산 -> 잠재 공간 변화 방향을 찾아 원본 이미지 머리 길이를 변경한 이미지 생성
Method
목표: 사전 학습된 Generator를 주어진 소스 도메인에서 텍스트 프롬트만으로 설명되는 새로운 타겟 도메인으로 전환하는 것
CLIP-based guidance
- Global Loss: styleCLIP의 Direct Loss 사용
- 수식: \(L_{\text{global}} = D_{\text{CLIP}} (G(w), t_{\text{target}})\)
- \(G(w)\): \(w\)로 생성된 이미지
- \(t_{\text{target}}\): 타겟 클래스 텍스트 설명
- \(D_{\text{CLIP}}\): CLIP 공간의 코사인 거리
- 초기 이미지나 도메인에 의존하지 않기 때문에 글로벌 손실로 명명
- adversarial solutions으로 이어질 수 있어 Generator 학습에 부적합하지만 Adaptive Layer Selection에서 활용
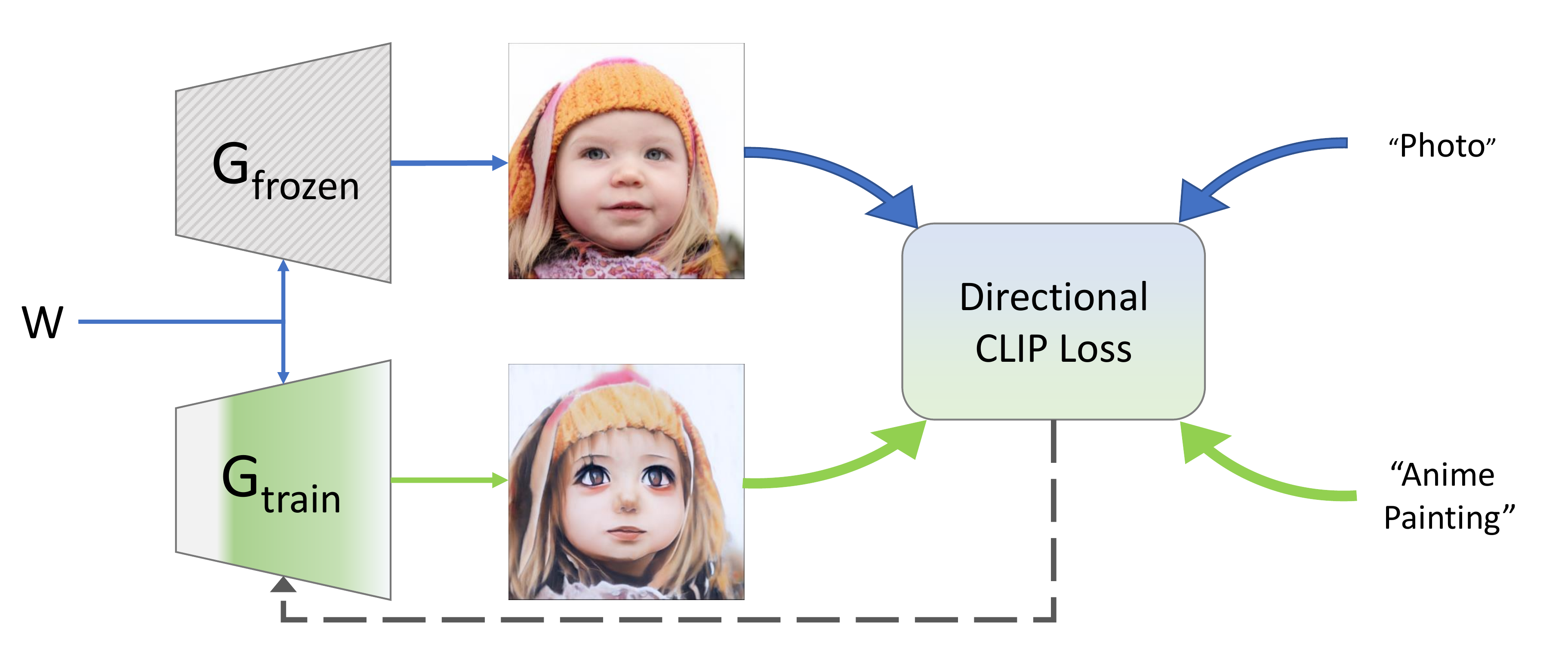
Directional CLIP Loss:
- 소스 도메인과 타겟 도메인 간의 방향성을 식별하는 방법
- 텍스트 프롬프트 쌍을 사용해 소스와 타겟 도메인을 설명해 CLIP 공간 방향성 식별
- \(G_{\text{frozen}}\) 생성기: 고정된 생성기로 소스 도메인 이미지 생성
- \(G_{\text{train}}\) 생성기: 훈련 중인 생겅기로 텍스트로 설명된 방향으로 소스 도메인 이미지를 변환하도록 fine tuning
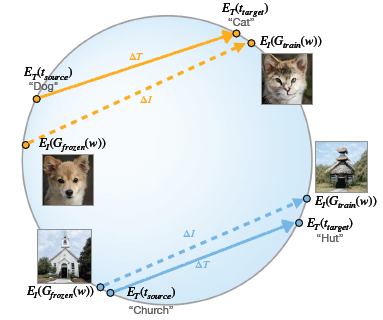
- 수식:
- \[\Delta T = E_T(t_{\text{target}}) - E_T(t_{\text{source}})\]
- \[\Delta I = E_I(G_{\text{train}}(w)) - E_I(G_{\text{frozen}}(w))\]
- \[L_{\text{direction}} = 1 - \frac{\Delta I \cdot \Delta T}{|\Delta I| |\Delta T|}\]
- \(E_I\)와 \(E_T\)는 CLIP의 이미지 및 텍스트 인코더
- \(t_{\text{target}}\)와 \(t_{\text{source}}\)는 타겟 클래스와 소스 클래스의 텍스트 설명
- \(\Delta T\)는 CLIP 공간에서의 텍스트 간 방향 벡터
- \(\Delta I\)는 생성된 이미지 간 방향 벡터
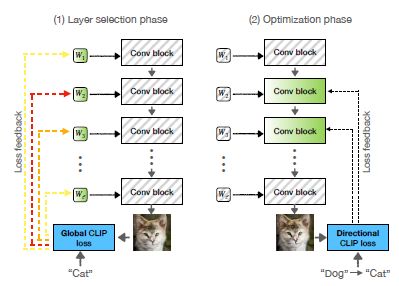
Layer Freezing:
- 긴 훈련으로 발생하는 네트워크 불안정 및 과적합 방지
- 가장 관련이 있는 가중치 식별
- 네트워크 가중치 일부만 최적화 및 훈련 정규화
Latent-Mapper ‘mining’
- 일부 형태 변경 작업에서 완전한 변환을 완료하지 못하는 경우 발생
- 소스와 타겟 중간 형태의 이미지로 생성하는 경우 모든 잠재 코드를 타겟 도메인과 유사한 영역으로 매핑
결과
