Stable Diffusion
카테고리 : TIL (Tody I Learned) >> Papers
Abstract
디퓨전 모델은 이미지 생성 과정을 노이즈 제거 오토인코더를 순차적 적용하는 방식으로 동작한다. 하지만 픽셀 공간에서 직접적으로 동작하여 반복적인 계산으로 많은 리소스가 든다. 이러한 한계를 극복하기 위해 사전 학습된 오토인코더의 잠재 공간에서 디퓨전 모델을 적용하는 방식을 소개한다.

Introduction
GAN(Generative Adversarial Networks) 모델은 이미지 생성에서 좋은 성능을 보이지만 비교적 제한된 다양성을 가진 데이터에 국한되어 있다. 디퓨전 모델은 다양한 데이터에 활용 가능하며 Inpainting, Colorization, Stroke 기반 합성 같은 작업에 뛰어난 성능을 보인다.
Democratizing High-Resolution Image
- 디퓨전 모델은 확률 기반 모델로 데이터의 인지하기 어려운 세부 사항을 모델링하는 데 과도한 리소스를 사용할 수 있음
- 고차원 공간에서 많은 계산 리소스가 요구됨
- 성능을 유지하면서 디퓨전 모델의 계산 요구 사항을 줄이는 것이 목표
Departure to Latent Space
- 픽셀 공간에서의 디퓨전 모델 분석
- 미세한 텍스처나 작은 디테일 등의 고주파 요소 제거
- 데이터 Semantic 및 Conceptual 구성 학습
- 고해상도 이미지를 직접 처리하는 것이 아니라 저차원 Latent Space로 변환 처리하여 계산 비용을 줄임
- 오토인코더를 통한 학습
- 오토인코더를 사용해 저차원 Latent Space로 변환
- Latent Space에서 디퓨전 모델을 학습시켜 고해상도 이미지 생성
- LDM(Latent Diffusion Models)라고 부름
- 한 번 학습시킨 오토인코더는 텍스트-이미지 합성, 인페인팅, 초해상도 생성 등 다양한 작업에 사용 가능
- Transformer 모델과 연결 가능
Related Work
GAN
- Density estimation 강조
- Density estimation이 좋다는 것은 생성한 데이터 샘플이 원본 데이터 분포와 잘 일치하여 다양한 샘플링과 현실감 있는 데이터 생성이 가능하다는 것을 의미함
- 고해상도 이미지를 효율적 샘플링이 가능
- 최적화가 어렵고 전체 데이터 분포를 캡처하는 데 어려움
- 특정 유형의 이미지에서는 잘 작동하지만 다양한 종류의 이미지를 생성하는 데 어려울 수 있음
Likelihood-based Methods
- Variational Autoencoders (VAE): 고해상도 이미지의 효율적 합성이 가능하지만 샘플 품질이 GAN만큼 높지 않음
- Flow-based Models: 고해상도 이미지의 효율적 생성이 가능하지만 샘플 품질이 GAN만큼 높지 않음
- Autoregressive Models (ARM): 계산 비용이 많이 들어 저해상도 이미지에 제한됨
Diffusion Probabilistic Models
- Density estimation과 샘플 품질 성능이 뛰어남
- UNet을 기반으로 한 신경망을 사용하면 자연스럽고 정확한 이미지 생성 가능
- 가중치를 조정하여 이미지 품질과 압축 성능 간의 균형 조절 가능
- 픽셀 공간에서 모델을 평가, 최적화하여 많은 계산 리소스가 필요하며 시간이 오래 걸림
- LDM 제안
Two-Stage Image Synthesis
- VQ-VAE(Vector Quantized-Variational Autoencoders): 입력 이미지를 인코더를 통해 저차원 잠재 벡터로 변환
- 잠재 벡터는 이산적인 codebook 항목으로 양자화 되는 것으로 가장 가까운 codebook 항목으로 변환되는 것
- codebook: 미리 정의되어 있는 이산적인 벡터들의 집합
- 잠재 벡터를 직접 사용하지 않아 저장 공간 절약이 가능
- 이산적인 표현을 사용해 모델 학습이 더 안정적이고 특정 패턴을 더 잘 학습할 수 있음
- 양자화된 잠재 벡터를 디코더로 다시 복원
- 이산화된 잠재 공간에서 ARM 모델을 사용해 이미지 표현적 사전 학습
- VQGAN(Vector Quantized Generative Adversarial Networks): VQ-VAE 개념을 확장해 고해상도 이미지를 생성하는 것
- VQ-VAE 인코딩 및 디코딩 과정을 유지하면서, 추가적으로 GAN의 Adversarial training을 도입
- Adversarial Training: 생성자(Generator)와 감별자(Discriminator)로 구성
- 생성자: 랜덤 노이즈 벡터를 입력으로 받아 실제 데이터와 유사한 가짜 데이터 생성
- 감별자: 실제 데이터와 생성된 가짜 데이터를 구별
- 생성자는 감별자를 속이도록, 감별자는 생성자가 생성한 가짜 데이터를 구별하도록 학습하여 실제 이미지와 유사한 이미지를 생성하도록 함
Method
Perceptual Image Compression
- 이미지의 특성을 유지하면서도 효율적으로 압축하는 것이 목표
- 원본과 생성된 이미지 간 고수준 특징을 비교해 이미지 유사성 측정
- Patch들에 대해 GAN의 Adversarial Training을수행하여 지역적 현실감 강화
- 오토인코더
- 인코더: 입력 이미지를 잠재 표현으로 인코딩
→ 수식: \(z = E(x)\) - 디코더: 잠재 표현 \(z\)를 사용하여 이미지 복원
→ 수식: \(\tilde{x} = D(z) = D(E(x))\) - 다운샘플링: 일정 비율(\(f\))로 다운샘플링하여 이미지 축소
- 인코더: 입력 이미지를 잠재 표현으로 인코딩
- KL 정규화: 잠재 공간이 너무 큰 분산을 가지지 않도록 함
- VQ 정규화: 디코더 내부 벡터 양자화 레이어를 사용해 잠재 표현을 이산적 코드북 항목으로 양자화
- 잠재 공간의 2차원 공간을 활용하여 1차원으로 변환하지 않고 Convolution을 활용해 2차원 구조를 유지해 고품질 이미지 생성이 가능해짐
Latent Diffusion Models
- 디퓨전 모델은 데이터를 점진적으로 노이즈 제거하는 방식으로 학습해 데이터 분포를 학습
- 노이즈가 제거된 버전을 예측하도록 학습
→ 수식: \(\mathcal{L}_{DM} = \mathbb{E}_{x, \epsilon \sim \mathcal{N}(0,1), t} \left[ \| \epsilon - \epsilon_\theta(x_t, t) \|_2^2 \right]\) - Perceptual Image Compression에서 학습한 모델 \(E\)와 \(D\)를 사용하여 저차원 Latent Space에 접근
- Latent Space에서 생성 모델은 더 중요한 부분에 집중하여 학습하고 효율적인 학습이 가능
- 2D 기반 UNet 기반 구조를 사용해 이미지 공간적 정보를 보존하고 집중 학습
→ 수식: \(\mathcal{L}_{LDM} := \mathbb{E}_{E(x), \epsilon \sim \mathcal{N}(0,1), t} \left[ \| \epsilon - \epsilon_\theta(z_t, t) \|_2^2 \right]\)
Conditioning Mechanisms
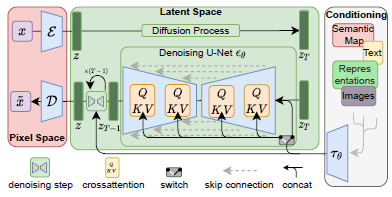
- 조건부 분포 모델링을 하여 텍스트 입력과 같은 조건에 따른 생성이 가능해짐
- Cross-Attnetion Mechanism을 통해 두 가지 다른 모달리티 사이의 상관관계를 학습
- Attention Mehanism: 입력 데이터의 각 부분이 다른 부분과 얼마나 관련 있는지 계산
- Cross-Attention: 두 가지 다른 종류 입력 데이터 사이의 상관관계 학습
- 어텐션 스코어 계산: \(\text{Attention}(Q, K, V) = \text{softmax}\left( \frac{QK^T}{\sqrt{d}} \right) V\)
- \(Q:\) 쿼리를 의미하며 현재 Attention 하고 있는 입력 데이터의 특정 부분
→ 수식: \(Q = W^{(i)}_Q \cdot \phi_i(z_t)\) - \(K:\) 키를 의미하며 다른 입력 데이터의 모든 부분
→ 수식:\(K = W^{(i)}_K \cdot \tau_\psi(y)\) - \(V:\) 값을 의미하며 실제 원하는 정보
→ 수식:\(V = W^{(i)}_V \cdot \tau_\psi(y)\) - 각 키가 쿼리와 얼마나 관련 있는지 평가
- 입력 \(y\)를 도메인 특정 인코더 \(\)\tau_\psi\(\)를 통해 변환
- \(Q:\) 쿼리를 의미하며 현재 Attention 하고 있는 입력 데이터의 특정 부분
- 조건부 LDM 학습
- 텍스트 설명 같은 조건 \(y\)를 도메인 특정 인코더 \(\tau_\psi\)를 통해 중간 표현으로 변환
- Cross-Attention Mechanism을 사용해 \(\tau_\psi(y)\)를 UNet 중간 레이어에 매핑
- 어텐션 스코어를 계산해 조건이 이미지 생성에 반영
- 조건부 손실 함수를 정의해 모델이 조건 \(y\)에 맞는 이미지를 생성할 수 있도록 학습
- 손실 함수는 모델이 예측한 노이즈와 실제 노이즈 간의 차이를 최소화하는 방식으로 정의
결과

