AdaBLDM
카테고리 : TIL (Tody I Learned) >> Papers
Abstract
이 논문은 산업 결함 탐지(Anomaly Detection, AD)을 개선하기 위한 새로운 알고리즘인 AdaBLDM을 소개한다. 산업 결함 탐지를 효과적으로 수행하기 위해서는 많은 결함 샘플들이 필요하기 때문에 높은 품질의 결함 샘플을 생성하기 위한 생성형 AI 모델을 설명하고 있다.
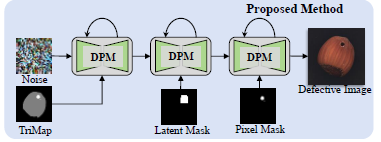
Introduction
AD 알고리즘
- 제조 공정에서 결함이 있는 샘플을 얻는 것은 결함이 없는 샘플을 얻는 것보다 어려움
- 대부분의 AD 알고리즘은 결함이 없는 샘플로 학습을 하고 해당 분포에 속하지 않는 샘플을 이상치로 간주
- 하지만 결함이 있는 샘플을 포함시키면 정확도가 크게 향상되지만 이는 데이터 분포 불균형으로 이어짐
- 실제와 같은 결함이 있는 샘플을 생성하는 것이 목표
개선 사항
- BLDM(Blended Latent Diffusion Model) 활용
- Trimap을 언어 프롬프트와 함께 사용
Related Work
Synthetic Defect Generation
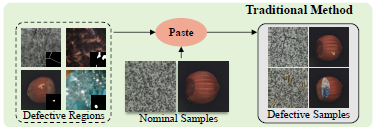
- 결함 모방 방식:
- 정상 이미지에 이상 픽셀을 붙여 결함 생성
- 새로운 결함 패턴을 생성할 수 없으며 과적합 문제 발생 가능성이 높음
- ex) Crop&Paste, PRN
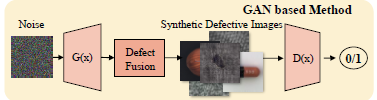
- 이상 패턴 생성 방식:
- 데이터셋에 Noise를 결합하여 결함 생성
- 생성된 결함의 분포가 실제 결함과 다를 수 있어 성능 향상 보장이 안됨
- ex) DRAEM, DeSTeg, MegSegm ReSynthDetect
- GAN(Generative Adversarial Networks):
- SDGAN: 두 개의 생성기를 사용하여 결함과 비결함 상태를 전환해 고품질 이미지 생성
- Defect-GAN: 비결함 이미지를 결함 이미지로 변환하여 결함 분류기 학습
- 결함의 위치가 부정확할 수 있음
Diffusion Probabilistic Models for Image Editing
- 디퓨전 모델은 고품질 이미지를 생성하는 데 적합하며 안정성이 좋음
- State of the art
- 주요 모델 예시
- LDM(Latent Diffusion Model): 저차원 Latent Space에서 이미지 생성 및 편집을 수행하여 높은 효율성 제공
- RePaint: 사전 훈련된 DDPM을 활용해 reverse diffusion 단계에서 주어직 픽셀을 샘플링하여 이미지 편집
- DCFace: 두 개의 Feature Encoder를 사용하여 얼굴 이미지 편집
- ControlNet: 기존 DPM을 제어하여 더 나은 합성 결과를 획득
- Dual-Cycle Diffusion: Unbiased mask를 생성해 이미지 편집
The Proposed Method
Task Definition and Preliminaries
- \(\text{X}_{OK}\): 결함 없는 정상 이미지들로 구성된 샘플 셋으로 학습용 데이터로 사용
- \(\text{X}_{NG}\): 결함 있는 이미지들로 구성된 샘플 셋으로 \(\text{X}_{OK}\) 의 수에 비해 매우 적음
- \(M_{NG}\): 결함 있는 부분에 대한 마스크로 \(\text{X}{NG}\)와 셋으로 구성
- 목표: 합성 결함 이미지를 생성하는 것
→ \(\{\text{X}_{OK}, \text{X}_{NG}, M_{NG}\} \xrightarrow{\text{Defect Generator}} \{\text{X}_{NG}^*, M_{NG}^*\}\)
Forward Diffusion Process
- 정상 이미지를 무작위 노이즈로 변환
- 원본 이미지를 점진적으로 노이즈로 변환하여 완전한 노이즈 \(x_T\)가 됨
→ \(q(x_t \mid x_{t-1}) = \mathcal{N}(x_t; \sqrt{1 - \beta_t} x_{t-1}, \beta_t I)\)
→ \(q(x_{1:T} \mid x_0) = \prod_{t=1}^T q(x_t \mid x_{t-1})\) (\(\beta_t\): Predifiend variance schedule)
Reverse Diffusion Process
- 노이즈에서 원본 이미지로 복원
- 노이즈에서 출발해 점진적으로 원본 이미지로 복원
→ \(p_\theta(x_{t-1} \mid x_t) = \mathcal{N}(x_{t-1}; \mu_\theta(x_t, t), \Sigma_\theta(x_t, t))\)
→ \(p_\theta(x_{0:T}) = p(x_T) \prod_{t=1}^T p_\theta(x_{t-1} \mid x_t)\) (\(\mu_\theta, \Sigma_\theta\): 신경망 모델로 근사화)
Latent Diffusion Model and Cross-Modal Prompts
Latent diffusion model with controlling information
- LDM은 이미지의 전처리된 Latent Feature Space에서 직접 작업 수행
- 입력 이미지: \(x \in \mathbb{R}^{H_x \times W_x \times 3}\)
- Latent Feature: \(z \in \mathbb{R}^{H_z \times W_z \times C_z}\)
- 인코딩: 입력 이미지를 인코더 함수 \(\Omega\)를 사용하여 변환
→ \(z = \Omega(x)\) - 디코딩: 디코더 함수 \(\Phi\)를 사용하여 원본 이미지로 복원
→ \(x = \Phi(z)\)
- Reverse diffusion에서 역방향 조건부 확률
- 수식: \(p_\theta(z_{t-1} \mid z_t, t, C) = \mathcal{N} \left(z_{t-1}; \frac{1}{\sqrt{\alpha_t}} \left( z_t - \frac{1 - \alpha_t}{\sqrt{1 - \bar{\alpha}_t}} \epsilon_\theta(z_t, t, C) \right), \sigma_t I\right)\)
- \(\epsilon_\theta\): 훈련될 \(\theta\) 파라미터가 설정된 심층 모델
- \(C\): LDM에 전달되는 제어 프롬프트로 생성 과정 안정화에 사용됨
- \(\alpha_t\, \bar{\alpha}_t, \sigma_t\): 각 단계 \(t\)에서 결정적으로 계산되는 파라미터
Linguistic prompts
- 생성 모델의 제어와 안정성을 위해 도입된 모듈
- 디퓨전 모델 등에서 정확도를 높이고 결과를 일관성 있게 만드는데 도움
- 정의: \(y:="\{obj\},\) \(a\) \(\{obj\}\) \(with a\) \(\{def\}"\)
- \(obj\): 객체의 범주를 의미 ex) 캡슐
- \(def\): 결함 유형 ex) 검은 오염
- 텍스트 인코딩: 텍스트 프롬프트는 파라미터가 고정된 텍스트 인코더 \(\tau\)를 통해 처리
- 수식: \(\tau : \mathbb{R}^{d_y} \to \mathbb{R}^{d_{\text{lang}}}\)
- \(\mathbb{R}^{d_y}\): 텍스트 임베딩 공간
- \(\mathbb{R}^{d_{\text{lang}}}\): 언어적 임베딩 공간
- 생성 모델 \(\epsilon_\theta\)에 언어적 제어 정보 공급
- KQ-V Attention 메커니즘을 통해 제어
Defect trimap prompts
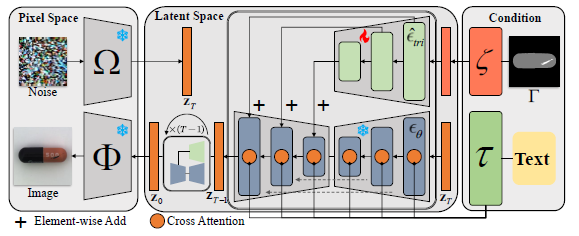
- 트리맵 \(\Gamma \in \mathbb{R}^{H_x \times W_x}\)는 생성된 객체와 결함의 원하는 위치를 지정
- 정의:
\(\Gamma(x, y) = \begin{cases} 1 & \text{if } \text{M}^*_{NG}(x, y) = 1, \\ 0.5 & \text{else if } F(x, y) = 1, \\ 0 & \text{else.} \end{cases}\) - 결함 마스크:
- 생성: \(M_{NG} \xrightarrow{ rand. i } \text{M}_{NG}^i \xrightarrow{\text{rand. affine}} \text{M}^A_{NG} \xrightarrow{\text{ fit F }} \text{M}^*_{NG}\)
- \(\text{rand. i}\): 무작위 인덱스 선택
- \(\text{rand.affine}\): 무작위 아핀 변환
- \(\text{fit F}\): \(\text{M}^A_{NG}\) 위치와 크기를 조정하여 \(F\)에 맞게 조정
- 트리맵 임베딩:
- Convolution block을 통해 임베딩: \(\zeta(\Gamma) \in \mathbb{R}^{H_z \times W_z \times C_z}\)
- 임베딩된 feature는 인코더 네트워크 \(\hat{\epsilon}_{tri}\)에 입력되어 “spatial attention” 모듈을 “self attention” 과정으로 대체 사용
- \(\hat{\epsilon}_{tri}\)에서 추출된 feature는 노이즈 제거 디코더 \(\epsilon_\theta\) 레이어에 요소별로 덧셈을 통해 주입됨
Loss Function and Training scheme
Loss Function
- \[L_{LDM} := \mathbb{E}_{z_t, C, \epsilon \sim \mathcal{N}(0,1), t} \left[ \|\epsilon - \epsilon_\theta(z_t, t, \tau(y), \hat{\epsilon}_{tri}(\zeta(\Gamma)))\|_2^2 \right]\]
Training scheme
- \(\epsilon_\theta\): MVTec AD와 같은 데이터셋을 사용하여 사전 학습. 학습 과정에서 \(\epsilon_\theta\)는 고정하고 하위 범주에 대해 학습
- \(\hat{\epsilon}_{tri}\): LDM 모델의 파라미터로 초기화되는 인코더이며 실제 결함 샘플을 기반으로 각 하위 범주에 대해 Fine tuning
- \(\zeta\): 트리맵 임베딩을 위한 Convolution block으로 실제 결함 샘플을 기반으로 처음부터 학습
- \(\Omega, \Phi\): VQ-VAE 알고리즘 모듈을 따라 배포되며 학습 동안 고정
- \(\tau\): CLIP의 텍스트 인코더를 사용하며 학습 동안 고정
Multi-Stage Denoising with Content Editing

1단계: Free Diffusion Stage
- \(T_1\) 단계 동안 진행
- Content editing 없이 결함 없는 데이터에 대해 Denoising만 수행
2단계: Latent Editing Stage
- \(T_2\) 단계 동안 진행
- 입력 feature \(z_t\)를 결함 없는 이미지 \(x_{OK}\)와 결합
- \(z_t\)는 \(M_{NG}^*\) 결함 마스크에 맞추어 수정 후 Denoising
3단계: Image Editing Stage
- \(T_3\) 단계 동안 진행
- 입력 feature \(z_t\)가 디코더 \(\Phi\)를 거쳐 이미지 공간으로 변환하여 \(x_t\) 획득
- 변환 이미지와 결합 없는 이미지 조합
- 수식: \(x_t \odot M_{NG} + x_{OK} \odot \neg M_{NG}\)
- 다시 잠재 공간으로 변환
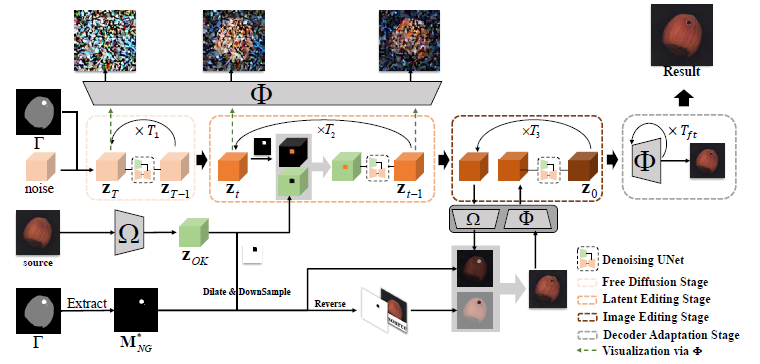
Online Decoder Adaptation

- Multi-Stage Denoising with Content Editing을 통해 얻어진 변환된 \(z_{NG}^*\)를 디코더 \(\Phi\)에 입력
- 디코더를 통해 이미지 복원
- 결함 없는 픽셀은 원본 \(x_{OK}\)와 유사하게 복원
- 결함 있는 픽셀은 디코더에 따라 복원
Implementation Details
Resize 이미지
- 이미지 크기: \(H_x = W_x = 256\)
- Latent space 해상도: \(H_z = W_z = 32\)
Latent Feature 채널 수
- 채널 수 \(C_z = 4\)
Affine 변환
- 무작위 회전 각도: \(\gamma \in [0^\circ, 360^\circ]\)
- 무작위 스케일링 인자: \(s \in [0.85, 1.15]\)
Anomaly Detection
- 나무나 직물 표면 같은 경우 결함 외에 모든 픽셀이 Foreground로 간주
최적화
- AdamW Optimizer 사용
- 학습률: \(1 \times 10^{-5}\)
- 베타 값: \(\beta_1 = 0.9, \beta_2 = 0.999\)
텍스트 프롬프트
- 10% 확률로 비어있는 텍스트 프롬프트를 모델에 입력
디노이징 DDIM 샘플링 단계
- Free Diffusion Stage: \(T_1 = 50\)
- Latent Editing Stage: \(T_2 = 30\)
- Image Editing Stage: \(T_3 = 5\)
Online Decoder Apation
- 최대 반복 횟수: \(T_{ft} = 200\)
- 보수적 비율: \(\lambda_{con} = 100\)
- 학습률: \(1 \times 10^{-4}\)